less is more, more or less
 less is probably the single most commonly used tool in the SysAdmin toolbag. less is a pager. It’s able to display the contents of a text file and enables scrolling through the file a page at a time. Its claim to fame is its ability to make it possible review large text files; files that are larger than your system’s memory. It does this by reading small segments of the file at a time. But what make less truly a power tool is it’s search ability.
less is probably the single most commonly used tool in the SysAdmin toolbag. less is a pager. It’s able to display the contents of a text file and enables scrolling through the file a page at a time. Its claim to fame is its ability to make it possible review large text files; files that are larger than your system’s memory. It does this by reading small segments of the file at a time. But what make less truly a power tool is it’s search ability.
NOTE: less is available on all modern Unix installations. It’s also available for Windows as part of Cygwin (http://cygwin.org). After you install Cygwin add it to your path and less will work from any command prompt.
A big part of any SysAdmin job is being able to extract information from log files. Often these log files are voluminous and contain information from a dozen or more sources. Finding the specific bit of information buried in the logs is like the proverbial needle in a haystack. Having a power tool like less makes the task manageable.
For our discussion, let’s assume you need to search through Apache web logs. If you’re not familiar with Apache log format, don’t worry – our goal here to get familiar with search and the apache log is just a nice place to experiment with. Open the file with the command:
$ less http-access.log
At its most basic level, search in less is straightforward text matching. To find a line with a piece of text, the command is forward slash ‘/’, followed by the text you want to find. less will search forward from the current position for lines with the matching text. It will put the first matching line at the top of the screen and highlight the match. If more than one line matches it will highlight those as well. To search backwards from your current position the command is question mark ‘?’.
Simple Search
Let’s say you want to search your apache log for all hits from Google’s web crawler. So you press forward slash, then type the search text:
robots.txt
Press enter to start the search. In our example, we received back the following.
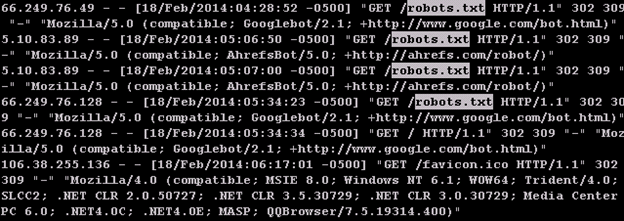
The first match is highlighted on the top line. You can see the web request came from the ip address 66.249.76.49 which according to whois is assigned to Google (we’ll cover whois in a future article). So we found a hit from the Google web crawler.
Notice three additional lines are highlighted. The second line matched our search text, but the ip address is 5.10.83.89 which is somewhere in the Netherlands and is not Google. Our goal is to search for Google web crawler hits, so this match is not what we were looking for. We’d like to refine our search to restrict our matches. This is perfect job for a regular expression search (‘regex’).
Regular expression search combines both simple text matching amplified with special meaning metacharacters and it’s these metacharacters that enable you to create incredibly flexible expression. You don’t need to know every aspect of regular expression to tap its power – just a few aspects are more than enough to get you started.
A few things to keep in mind. Search in less is always line based; meaning each line of text in the file will be scanned and less will only stop searching when it finds a matching line. You can interrupt a long running search with CTRL-C. This will cancel the search and return you to where you started.
We recommend you build regex searches in easy steps. Start with a simple pattern and build from there. If you try to get too advanced from the start, you’ll spend too much time wondering if your regex is flawed or if the search text does not exist in the file.
First Regular Expression Search
Now to build on our previous example, let’s assume we want to find every line that has both the text ‘robots.txt’ followed by the text ‘Googlebot’. The search expression we could use is:
robots\.txt.+Googlebot
Using this search text on our example file results in the following matches.
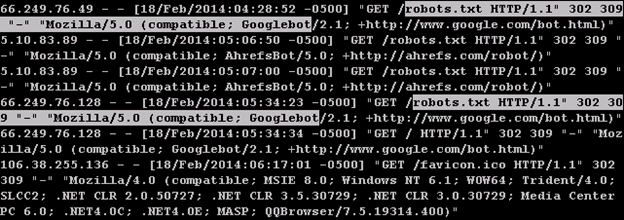
You’ll notice less now only highlights those lines that include the web crawler lines from the Googlebot. You’ll also notice that the highlighted area of each line includes more characters. This is how less indicates which parts of the line contributed to the match and is useful to watch when experimenting with regex.
Let’s break down the search string. The first part our search is ‘robots’.
robots\.txt.+Googlebot
This first part is ‘literal’ text. Literal text instructs the regex engine to match each character’s literal value with no special meanings.
The next part of the search is a backslash followed by a dot.
robots\.txt.+Googlebot
The backslash is the escape character. Its purpose is to remove the special metacharacter status of the character that follows it, which in this case is the dot. The dot is the regex wildcard metacharacter which would typically match any character. The backslash removes the dot’s wildcard characteristic and instead says to match a literal dot.
The next part of the search is ‘txt’
robots\.txt.+Googlebot
This is literal text, and will match the literal characters ‘txt’
The next part of the search is dot-plus
robots\.txt.+Googlebot
The dot metacharacter is the wildcard. It will match any single literal character. The plus is a repetition metacharacter. It bonds the preceding element and causes it to match one or more instances of it. By using plus after a dot, we are asking less to search the line for one or more characters, but we don’t really care what those characters are.
The final part of the search is ‘Googlebot’
robots\.txt.+Googlebot
This is literal text that requires the literal characters ‘Googlebot’.
Putting all the pieces together, the search expression says to match the text ‘robots.txt’ followed by one more miscellaneous characters, followed by the text ‘Googlebot’.
Refined Regular Expression
Let’s try another search. This time, let’s says we want to search for other traffic from Google’s IP address that is being used by the web crawler we found in our last search. This is a common work pattern when working with less, the first match causes you to have new questions that then lead you onto others.
In the last search, we saw Google’s web crawler was coming from the address 66.249.76.128. A quick check of whois reveals this IP is associated with the network block 66.249.64.0/19. This includes all the addresses within the range 66.249.64.0 – 66.249.95.255. Let’s develop a regular expression for apache hits coming from within this range.
The search expression we could use is:
^66\.249\.[6-9]
Using this search text on our example file results in the following matches.
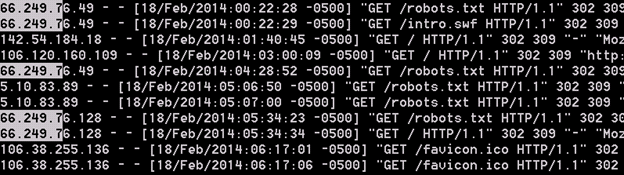
Let’s break this down. The search starts with a caret ‘^’
^66\.249\.[6-9]
The caret is a metacharacter. It is referred to as the start-of-line anchor as it anchors the search to the start of a line. The text that comes after it must be the first elements of a line.
Let’s move a bit quicker here. The next part of the search text is ‘66\.249\.’
^66\.249\.[6-9]
This will match the literal text ‘66’ followed by a dot followed by ‘249’.
The final part our the search text is ‘[6-9]’
^66\.249\.[6-9]
The square brackets start a character class expression. It is used to require a match for a single character that occurs within the brackets. The dash character within the brackets allows us to create a range expression to match any number from 6 to 9. A more verbose way to create the same range is to list each element in brackets; eg: ‘[6789]’
Advanced Regular Expression
Before we look at advanced regular expression a word of caution. Try to resist the urge to get the search expression perfect. Most of the time, you just need to get close enough and if you stick with what you know about regex, you can usually do so.
If you study the last search, you’ll notice we didn’t quite achieve our goal for only matching Google’s address block. Recall the range of valid IP’s is 66.249.64.0 – 66.249.95.255. But because we only searched the first character of the third octet of the address, it’s possible we could find lines that match addresses such as 66.249.63.X, or 66.249.96.X, both of which would be outside the range we wanted. You can write a search expression that will match the intended range precisely, but it requires a longer, more complex search.
Here is the search expression that will only match the /19 of Google’s address space
^66\.249\.(6[4-9]|[78]\d|9[0-5])\.
We’re going to focus on the search text in parenthesis.
(6[4-9]|[78]\d|9[0-5])
The parenthesis creates a capture group. Capture groups have several uses in regular expressions, one of which is called alternation. Alternation is how you can introduce an either-or expression. Let’s see how this works.
Starting from the left side of the capture group, we see the literal text ‘6’, followed by the bracket expression ‘[4-9]’. This will match the literal ‘6’ followed by any of the characters in the range from 4 to 9 (eg: 64, 65, 66, etc…).
Next we encounter the ‘|’ alternation metacharacter. This metacharacter says to match either what came before it OR what comes after it.
Next we encounter another bracket expression ‘[78]’ which will match either the literal ‘7’ or the literal ‘8’. This is followed by the ‘\d’ character class. The ‘\d’ character class will match any number from 0-9.
We then encounter another ‘|’ alternation metacharacter, which again says to match either what came before it OR what comes after it.
Finally, we encounter the literal ‘9’ which will match the literal character ‘9’. This is followed by ‘[0-5]’ which will match any number from 0-5.
Rendered into English, the capture group would require the search to match any number from 64-69 or 70-89 or 90-95.
Regex Further Reading
There are several good books and online resources for learning about regular expressions. If you’d like to interactively experiment with regex expressions, you can use this online site http://www.regexr.com. The site allows you to enter text you are trying to match, and then through a series of experiments, try different expressions until you get a successful match.